AI Evaluation: 5 Methods To Measure The Real Performance Of AI Systems

AI evaluation is often treated as the final checkpoint in an AI project, the moment when teams verify that a model works before releasing it into production. Yet in practice, many of the biggest problems with AI systems only become visible when evaluation is taken seriously.
A model that appears to improve after retraining may simply be reacting to changes in testing data. A system that performs well in controlled experiments can struggle once it encounters unfamiliar inputs. Without a consistent way to measure performance, it becomes difficult to tell whether a model is genuinely getting better or just producing results that look convincing.
This blog explores how AI evaluation works in practice, why it has become increasingly important for organizations deploying AI systems, and which metrics and methods are commonly used to measure performance.
What is AI Evaluation?
AI evaluation describes the process of measuring how well an AI system performs when applied to real tasks and datasets. Rather than relying on demos or isolated test results, teams use structured experiments and performance metrics to understand how a model behaves under different conditions.
Traditional software testing usually focuses on verifying whether specific functions operate correctly. AI systems introduce an additional layer of complexity. Model performance depends heavily on the data used during training and testing, and results can shift once the system encounters new inputs.
To understand these differences, AI evaluation usually involves several core activities:
- Preparing evaluation datasets that represent realistic scenarios
- Running controlled experiments to observe model outputs
- Measuring performance metrics such as accuracy, recall, latency, or error rates
- Analyzing failure cases to understand where the model struggles
An important part of this process is data labeling. Evaluation datasets need verified answers so that model predictions can be compared against a trusted reference. Labeled data serves as that reference.
Read more: Data Labeling: The Work That Makes AI Work
Many evaluation pipelines, therefore, rely on datasets created through rigorous data labeling workflows. Each example is checked and validated before it becomes part of a benchmark used to assess model performance. Without high-quality data labeling, measuring an AI system’s true capabilities becomes extremely difficult.
Why AI Performance Should Never Be Judged by “Gut Feeling”
It’s not unusual to see AI performance being judged through quick, informal checks. A chatbot is tested with a handful of prompts and seems to respond well. A recommendation system looks promising because internal teams find the results relevant. The problem is that these impressions rarely reflect how the system behaves outside controlled testing.
“Looks correct” Doesn’t Always Mean It’s Useful
A chatbot can return answers that are perfectly structured, grammatically clean, and still leave users stuck. A recommendation engine can drive more clicks, yet those clicks don’t turn into actual purchases. Nothing is technically “wrong” in these cases. The system is doing what it was designed to do. But somewhere along the way, it loses alignment with what users actually need.
That disconnect usually comes from how performance is measured. Most internal metrics focus on whether the model behaves as expected, whether it classifies correctly, responds within limits, or follows predefined patterns. What they miss is the outcome: does the output help someone move forward, make a decision, or complete a task?
Early Testing Rarely Reflects Production Data
Early evaluations tend to reuse patterns the model has already seen, similar phrasing, similar structures, and contexts. The outputs feel accurate partly because they resemble the data the model was trained on. Once the input drifts away from that familiarity, the behavior begins to shift as well.
Gartner estimates that up to 85% of AI projects fail to deliver expected outcomes, with poor data quality and a lack of proper validation among the leading causes. Without evaluation datasets that reflect these conditions, and without dependable data labeling to anchor what “correct” means, issues tend to surface only after the system is already in use.
Performance Only Matters when It Connects to Outcomes
There is also a disconnect between technical validation and business expectations. A model can achieve strong accuracy scores and still fail to create meaningful impact if those scores are not tied to real outcomes. What organizations care about tends to be more concrete:
- Whether processes become faster in practice
- Whether manual effort is actually reduced
- Whether errors decrease in a measurable way over time
Findings from McKinsey & Company suggest that companies seeing value from AI are those that translate model performance into operational metrics early on.
Why Businesses Can’t Ignore AI Evaluation
Risk Reduction
In practice, AI systems tend to produce outputs that are slightly off rather than completely wrong, which makes problems easy to dismiss during early stages. A response may sound convincing but carry inaccurate information, or a model may handle most cases well while quietly struggling with specific inputs that do not appear frequently in test data.
When these situations repeat across large volumes of interactions, they begin to affect operations in subtle but measurable ways, such as longer handling time, more manual intervention, or inconsistent decision-making. A structured evaluation process helps teams spot these patterns early, giving them a chance to address the source of the issue while it is still contained.
Continuous Model Improvement
Improving model performance requires more than adding new data or retraining on a larger dataset, it depends on having clear visibility into where the system breaks down in real usage. When that visibility is missing, updates tend to be broad and less effective, which slows down progress and makes improvements harder to measure.
A well-defined evaluation approach provides concrete signals that guide iteration, allowing teams to focus on specific failure cases, refine data quality, and adjust how the model responds in different scenarios.
Stronger Product Credibility
Users rarely think about model performance in technical terms. What they notice is whether the system behaves consistently enough to rely on. A product that delivers strong results most of the time but behaves unpredictably in certain moments quickly loses credibility.
Teams that invest in evaluation tend to deliver more stable experiences, which builds confidence over time. That consistency often matters more than peak performance, especially in products.
Compliance and Governance
Regulatory expectations around AI are becoming more concrete, with increasing demand for transparency in how models are tested, validated, and monitored. Organizations are expected to provide evidence that their systems have been assessed thoroughly and that potential risks have been considered throughout the lifecycle.
Evaluation provides the structure needed to answer those questions. It creates a clear record of how the system has been assessed and improved, which becomes essential not just for internal use but also for audits, regulations, and external review.
Key Metrics for AI Evaluation
Accuracy
Accuracy is often the first number teams reach for, and for good reason, it’s simple and easy to communicate. The problem is how quickly it becomes misleading. In datasets that are even slightly imbalanced, accuracy starts to reflect data distribution more than actual model capability. A model can look “good on paper” while consistently missing the cases that matter.
- Useful for tracking overall trends across iterations
- Easily inflated in datasets with dominant classes (e.g. 90% of one label)
- Says very little about performance on edge or minority cases
Recall
At some point, raw correctness stops being the right question. What matters more is how the model is wrong. Precision and recall force that distinction, and in practice, this is where evaluation starts to become meaningful.
A model with high precision but low recall behaves very differently from one with the opposite profile, even if their overall scores look similar. In real systems, that difference translates directly into risk, cost, or user experience.
- Precision indicates how trustworthy positive predictions are
- Recall reflects how much of the relevant signal is actually captured
- The trade-off is usually driven by business priorities, not model design
- Highly sensitive to inconsistencies in data labeling
F1-score
F1-score tends to appear when teams want a single number that “summarizes everything.” It works well for comparison, especially in imbalanced datasets, but it also smooths over important details.
Two models with the same F1-score can behave very differently in practice. That’s why it’s useful as a reference point, but rarely enough on its own.
- Combines precision and recall into a single score
- Common in benchmarking and model comparison
- Less effective for diagnosing specific performance issues
Confusion Matrix
When aggregate metrics start to feel abstract, the confusion matrix brings things back to something more tangible. Instead of summarizing performance, it shows exactly how predictions are distributed across different outcomes.
This is often where unexpected patterns show up, such as a model consistently over-predicting one class, or failing in a very specific scenario that doesn’t impact overall accuracy enough to be noticeable.
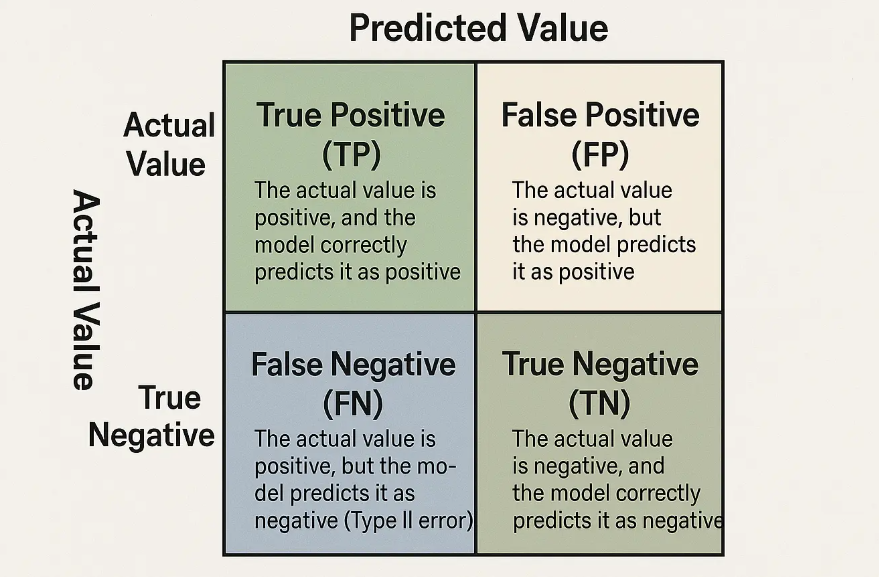
- Breaks predictions into TP, FP, TN, and FN
- Makes error distribution visible rather than implied
- Particularly useful for identifying systematic mistakes
Coverage
Some evaluation results look stable simply because the test data is too narrow. Coverage addresses that by focusing on what has not been tested, rather than what has.
A model trained and evaluated on clean, well-structured data can struggle as soon as it encounters variation, typos, incomplete inputs, or unexpected formats. This is especially common in production environments and is closely tied to how data labeling is handled.
- Measures how well evaluation data reflects real-world variation
- Helps identify missing edge cases
- Strongly influenced by the scope and quality of data labeling
Common Methods for Evaluating AI Systems
Benchmark Testing
Most teams start with benchmark testing, but not in the abstract way people often describe it. In practice, this usually means taking a labelled dataset, often a mix of internal data and curated samples, and running the model against it to see if it meets a minimum performance threshold.
For example, a team building a document classification system might prepare a few thousand labelled samples across different categories, then check whether the model can consistently classify them above a certain accuracy or F1-score. If performance drops significantly on specific categories, that’s often a signal that the data labeling in those areas needs to be refined rather than the model itself.
- Often used as a “go / no-go” checkpoint before moving forward
- Quickly exposes weak spots tied to specific labels or categories
- Highly dependent on how representative the labelled dataset is
Cross-Validation
Cross-validation tends to happen quietly during development, but it’s one of the ways teams avoid being misled by a “lucky” result. Instead of trusting a single train-test split, the dataset is rotated multiple times to see if performance stays consistent.
In a real scenario, a model might show 92% accuracy in one split but drop to 85% in another. That gap usually points to instability, often caused by uneven data distribution or inconsistent data labeling across subsets. Teams use this method because it answers a practical question: Is this model stable enough to trust, or just performing well on one version of the data?
- Helps detect unstable performance early
- Reveals hidden data distribution issues
- Often highlights inconsistencies in labelling quality
A/B Testing
Once a model is deployed, evaluation becomes less about metrics in isolation and more about actual user impact. A/B testing is where things start to get real.
For instance, a chatbot team might deploy two versions of a model: one optimized for accuracy, another for faster response time. Even if the first model performs better offline, the second might lead to higher user engagement simply because it feels more responsive.
- Compares models under real usage conditions
- Captures user behavior that offline testing misses
- Often reveals trade-offs between quality and experience
Human-In-The-Loop Evaluation
Some outputs simply can’t be judged by metrics alone. In content generation, summarization, or customer support automation, teams often rely on human reviewers to score outputs based on clarity, relevance, or usefulness.
In practice, this looks like setting up annotation workflows where reviewers evaluate model responses against predefined criteria. If those criteria are vague or inconsistent, the evaluation quickly becomes unreliable, this is why structured data labeling guidelines are critical even at this stage. For example, two reviewers might rate the same response differently unless there is a clear definition of what counts as a “good” answer.
- Used when quality is subjective or context-dependent
- Requires strict guidelines to reduce reviewer bias
- Closely tied to annotation and labelling workflows
Red Teaming and Stress Testing
Some issues only appear when the system is pushed in ways normal users wouldn’t try. Teams deliberately test the model with tricky, ambiguous, or even adversarial inputs. For example, prompting a language model with incomplete instructions, conflicting context, or edge-case scenarios to see how it responds.
In many cases, these findings don’t just lead to model adjustments, they trigger updates in data labeling, adding new edge cases into the training and evaluation datasets.
- Designed to uncover hidden or extreme failure cases
- Commonly used for LLMs and AI agents
- Feeds directly back into improving evaluation datasets
Conclusion
A model that looks good in testing does not always hold up in production. That gap is exactly what AI evaluation is meant to close. When metrics are tied to real scenarios and supported by reliable data labeling, performance becomes something you can measure, compare, and improve, not just something that “feels right.”
In practice, strong AI systems come from tight feedback loops between evaluation, data, and iteration. The teams that get this right are not the ones using the most metrics, but the ones who know which signals matter and how to act on them.
If you are looking to make your AI systems more reliable, it may be time to rethink how you approach evaluation and data labeling. Contact Icetea Software to explore how a structured AI evaluation process can help you build systems that perform consistently in real-world conditions.
————————————————————————
Icetea Software – Revolutionize Your Tech Journey!
Website: iceteasoftware.com
LinkedIn: linkedin.com/company/iceteasoftware
Facebook: Icetea Software





