Agentic AI ROI: How to Measure and Maximize Business Value in 2026!

Agentic AI ROI is no longer a theoretical question – it is the most urgent conversation in enterprise boardrooms in 2026. Companies that have deployed AI agents correctly are reporting an average return of 171%, with US enterprises averaging 192%. That is three times the return of traditional automation. But here is the uncomfortable truth sitting alongside those numbers: 40% of agentic AI projects will be cancelled by the end of 2027, and 88% of agents never make it from pilot to production. The gap between the winners and the failures is not the technology. It is whether organizations have a clear framework to measure what their agents are actually delivering – and a deployment model designed to maximize that value from day one. This guide gives you both.
The agentic AI ROI landscape at a glance
| 171% average ROI from agentic AI deployments (192% in US enterprises) Source | 74% of executives report achieving ROI from AI agents within the first year Source |
| 40% of agentic AI projects cancelled by 2027 – primarily due to unclear ROI Source | 88% of AI agents fail to reach production – infrastructure and governance gaps are the primary causes Source |
Why Agentic AI ROI Is Different From Any ROI You Have Measured Before
Most ROI frameworks were built for static tools – software that does the same thing every time you use it, where the cost is fixed, and the output is predictable. Agentic AI does not fit that model. An AI agent system improves over time, operates around the clock, handles edge cases it was not explicitly programmed for, and can compound its output in ways that traditional automation cannot.
This means measuring agentic AI ROI correctly requires thinking differently from the start. The immediate cost savings are real and measurable – but they are only part of the picture. The compounding returns from an agent that continuously learns, optimizes, and takes on more complex tasks over its deployment lifetime often dwarf the initial gains.
The PwC reality check: In 2026, executives have ‘little patience for exploratory AI investments’ – every dollar of agentic AI spend must now be tied to measurable outcomes. The era of proof-of-concept without accountability is over.
The 4-Pillar Agentic AI ROI Framework
The most practical agentic AI ROI framework currently in use by Fortune 500 companies breaks measurement into four distinct pillars. Every agent deployment should show movement on at least two of them – with at least one producing hard-dollar impact. Organizations that measure only one pillar (usually cost reduction) are running a cost-cutting exercise, not building a competitive advantage.
| 1 Cost Reduction Hard-dollar savings: labor displaced, process time reduced, error remediation avoided Example: $100M removed from support function (Salesforce) | 2 Revenue Acceleration New pipeline generated, conversion rates improved, retention gains Example: $1.7M pipeline from dormant leads (Salesforce SDR Agent) | 3 Quality & Risk Error rate reduction, compliance improvement, defect prevention Example: 2.5M diagnostic errors prevented annually (healthcare AI) | 4 Speed & Throughput Cycle time compression, throughput volume increase, time-to-market reduction Example: Reports cut from 15 days to 35 minutes (Fortune 500 finance) |
Pillar 1: Hard-Dollar Cost Reduction
This is the most straightforward pillar to measure and the most common starting point. Identify the cost of the workflow before agent deployment – labor hours, error remediation costs, tooling overhead – then measure the same workflow after deployment. The difference is your cost takeout.
- Baseline metric: cost per resolved ticket/cost per processed document/cost per completed workflow
- Post-deployment metric: same KPI at 30, 60, and 90 days post-launch
- Watch for: per-task compute costs on reasoning models, which can be 10x higher than simple chat completions
- Real benchmark: Salesforce Customer Zero removed $100M from support across 380,000+ interactions; 84% autonomous resolution rate
Pillar 2: Revenue Acceleration
Revenue impact is harder to attribute but more powerful than cost savings for securing sustained investment. Measure pipeline generated by agent-assisted prospecting, conversion rate improvements on agent-handled inquiries, and retention gains from proactive agent interventions.
- Baseline metric: conversion rate, pipeline value per rep, churn rate
- Post-deployment metric: same KPIs for agent-handled cohort vs. control group
- Real benchmark: Salesforce internal SDR Agent worked 43,000+ dormant leads, generating $1.7M in new pipeline
- Real benchmark: Grupo Globo – 22% improvement in retention rates within three months of agent deployment
Pillar 3: Quality and Risk Reduction
Quality improvement is often the most surprising value driver – and the hardest to quantify until you see it. Agents apply policy consistently, never have bad days, and create full audit trails. In regulated industries, this is not a nice-to-have; it is a competitive and compliance requirement.
- Baseline metric: error rate, compliance violation frequency, escalation rate
- Post-deployment metric: same KPIs, plus agent audit trail completeness
- Real benchmark: 1-800-Accountant – 70% autonomous resolution during 2025 tax season; 1,000+ engagements in first 24 hours
- Real benchmark: Wiley – 40%+ improvement in case resolution vs. previous chatbot; 213% ROI
- Finance: 2.8x return on agentic AI investments in telecom (Microsoft Copilot MWC 2026 case)
Pillar 4: Speed and Throughput
Speed improvements create compounding competitive advantages that do not show up on a cost spreadsheet but are felt in market position. Faster delivery cycles, higher throughput with the same team size, and faster time-to-market for software products all generate measurable business value.
- Baseline metric: average cycle time, tasks completed per FTE per day, time-to-deploy (for dev teams)
- Post-deployment metric: same KPIs at 30/60/90 days
- Real benchmark: Fortune 500 finance – report generation time from 15 days to 35 minutes; cost from $2,200 to $9 per report
- Real benchmark: McKinsey (150 enterprises, Feb 2026) – 46% reduction in routine coding time, 35% shorter code review cycles
- Real benchmark: AtlantiCare – 66 minutes saved per physician per day across 50 providers
How to Calculate Agentic AI ROI: A Step-by-Step Guide
The four pillars tell you what to measure. This five-step process tells you how to capture those measurements reliably – before you build anything, during the pilot, and through to production. Organizations that skip Step 1 (baseline capture) consistently fail to prove ROI, even when their agents are genuinely delivering value.
Step 1: Capture a clean baseline before you deploy anything
This is the single most important step and the one most teams skip. You cannot prove ROI without knowing what performance looked like before the agent. Document: average time per task, cost per task (labor + tooling), error rate, throughput volume, and escalation rate. Capture this data for at least two to four weeks before deployment. Shawn Kanungo’s Fortune 500 framework is explicit: 80% of failing pilots never captured a baseline.
Step 2: Define success metrics before you write a line of code
Map each metric to one of the four pillars. Be specific: ‘reduce cost per support ticket from $12.50 to under $5.00’ is a measurable target. ‘Improve efficiency’ is not. Every metric you choose should be directly influenced by the agent’s actions – not a proxy metric that could change for other reasons.
Step 3: Apply the ROI formula with compounding value in mind
Base ROI formula: ROI% = ((Total Value Generated – Total Cost of Deployment) / Total Cost of Deployment) x 100
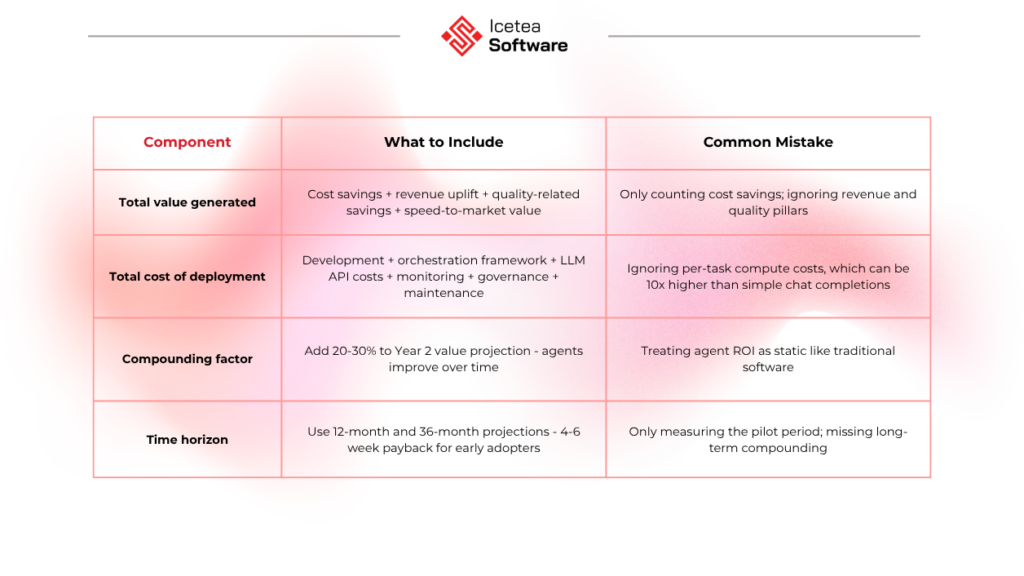
Step 4: Measure at the team level, not the agent level
Anthropic and Carnegie Mellon research confirmed that AI agents still make too many mistakes to be measured in isolation for high-stakes workflows. Mature deployments use human-plus-agent teams, and ROI should be measured at the team level: what does the combined human-agent team produce versus what the human-only team produced before?
Step 5: Track compute costs continuously – they can silently erode ROI
An agent that takes 45 tool calls to complete a task can cost ten times what a simple completion cost a year ago. If you are not monitoring per-task compute cost in real time, you may be generating impressive output metrics while destroying margin. Set cost-per-task alerts and review model selection regularly – the right model for the right task is one of the highest-leverage ROI decisions you can make.
Why 40% of Agentic AI Projects Fail on ROI – and How to Avoid It
Gartner’s 40% cancellation prediction is not a verdict on the technology – it is a verdict on the deployment model. The organizations that fail share the same four problems, and none of them are technical.
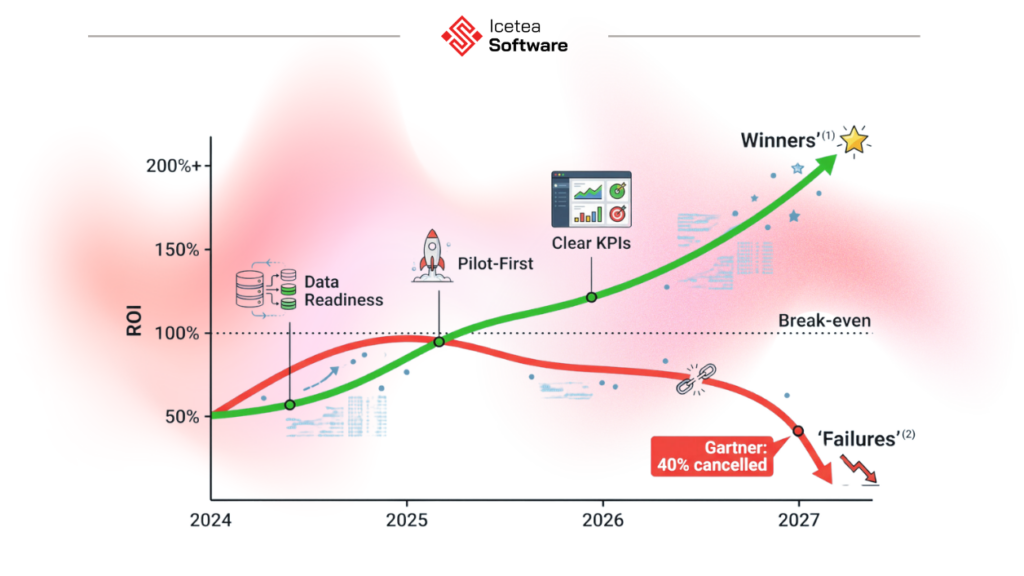
The 4 most common reasons agentic AI projects fail to deliver ROI
- They measured inputs instead of outcomes: ‘We rolled agents out to 5,000 employees’ is adoption data, not ROI. That is a vanity metric.
- They chose the wrong workflow: agents were pointed at tasks with no dollar value attached, so even perfect execution produced no measurable business impact.
- They ran the pilot without a baseline: if you do not know what cost and output looked like before the agent, you cannot prove what changed after.
- They confused ‘interesting demo’ with ‘deployable value’: most pilots work in a vacuum and collapse in production because nobody mapped the real workflow end-to-end.
The 4 attributes of the 12% who succeed:
- Pre-deployment infrastructure investment: clean data pipelines, API integrations, governance documentation before the agent is built
- Governance documentation before deployment: defined oversight model, audit trail design, human checkpoint architecture
- Baseline metrics captured before pilots: at least 2-4 weeks of pre-agent performance data
- Dedicated business ownership: a named person accountable for post-deployment ROI performance – not just the IT team
Source: Digital Applied – 150+ Agentic AI Statistics 2026
How to maximize agentic AI ROI from deployment day one:
- Start with 3-5 high-value use cases, not a company-wide rollout: organizations that see payback in 4-6 weeks start focused
- Ground agents in clean, well-governed data: 35% of organizations cite cybersecurity as the top barrier; 30% cite data quality
- Choose architecture that matches task complexity: over-engineering with multi-agent when single-agent suffices 3-15x inflates costs
- Build human oversight from the start: 84% of executives are comfortable with autonomous AI for specific processes, but only when oversight exists
- Monitor and iterate monthly: agentic AI ROI compounds – organizations that actively optimize agent performance after deployment see 2.8x returns vs. those that set-and-forget
Agentic AI ROI Is Yours to Capture – or Yours to Lose
The data is clear: organizations that deploy agentic AI correctly achieve average returns of 171%, with payback in weeks rather than months. But the 40% failure rate is equally real – and it is almost entirely preventable. The difference is a structured measurement framework, a clean baseline, and a deployment model that ties every agent action to a measurable business outcome.
In 2026, ‘we are exploring agentic AI’ will no longer be an acceptable answer to a board that wants to see financial results. Every deployment needs a clear ROI thesis, a four-pillar measurement plan, and a named business owner accountable for the numbers. Get those three things right, and agentic AI stops being an IT initiative and starts being a line item in the CEO’s growth strategy.
If you’re considering how agentic AI can fit into your organization, or how an IT outsourcing partner can help you bring it to life, we’re here to support that journey.
Get in touch with our team to explore tailored solutions that combine deep technical expertise with a practical understanding of enterprise needs.
————————————————————————
Icetea Software – Revolutionize Your Tech Journey!
Website: iceteasoftware.com
LinkedIn: linkedin.com/company/iceteasoftware
Facebook: Icetea Software





